










随着技术的不断发展,技术的种类越来越多,人们不可能掌握全部的技术,但是技术对于人们的选择有了太多太多,这时候在选择什么技术的时候,人们往往就会陷入迷茫,不知道应该选择什么样的技术,不清楚自己应该从什么技术下手,甚至说会怀疑技术的作用,认为有些技术没有意义,不知道有什么用。今天我们探讨一下数据科学领域内的技术存在的意义,分析一下大数据分析是否鸡肋,在数据科学技术体系中,高价值技术到底是什么,以及在人工智能领域中反对派的声音越来越大的时候,人工智能是否还能走下去,还能走多远?
大数据技术:计算资源无限,世界将会是怎样
大数据分析并不鸡肋
在计算机诞生的70年后,单台计算机的计算性能逼近物理极限,伴随计算机发展的摩尔定律逐渐失效。在这70年的发展过程中,刚开始是可以用摩尔定律进行准确的描述的,1965年,英特尔创始人之一戈登摩尔在考察计算机硬件的发展规律后,提出了著名的摩尔定律:
该定律认为,同一面积芯片上可容纳晶体管的数量,每隔16-24个月将翻一倍,计算性能也将翻一倍。换而言之,也就是每隔16-24个月,单位价格可购买到的计算能力将翻一倍。在随后的几十年内,摩尔定律被无数次的被印证。而直到现在,计算机性能已经逼近极限的情况下,摩尔定律似乎已经失效了。
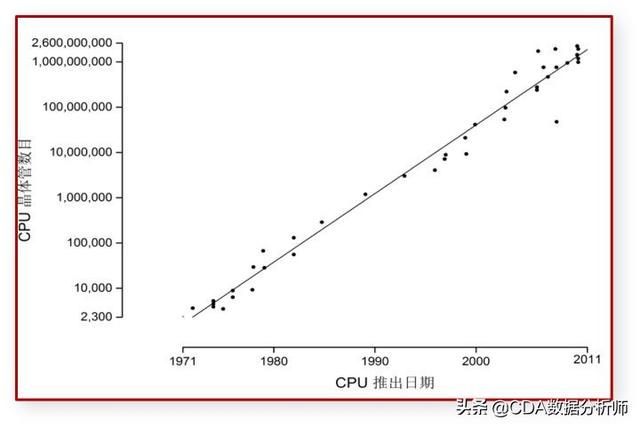
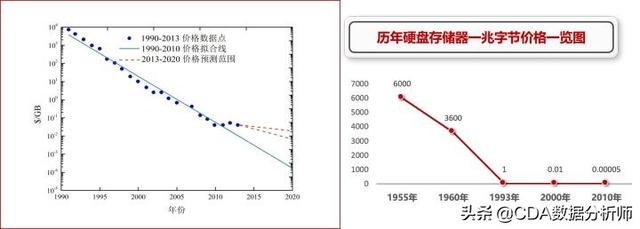
发展的期间伴随着摩尔定律不断的生效,在计算机方面同步发展的还有网络宽带和物理的存储容量,半个多世纪以来,存储器的价格几乎下降到原来价格的亿分之一。
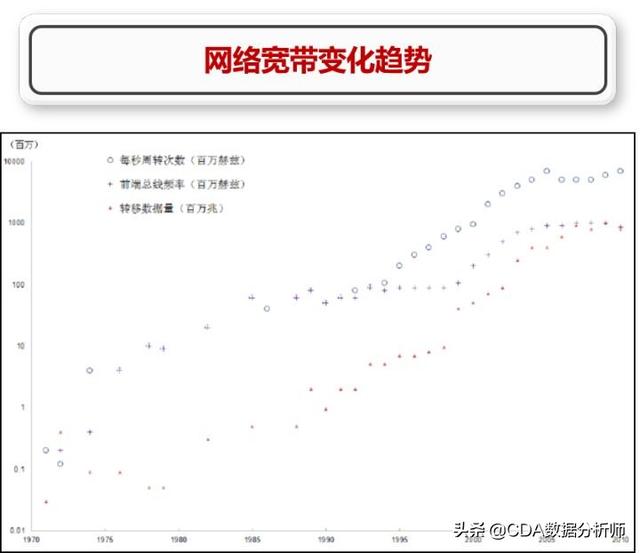
而网络宽带的的速度也在不断的突破极限。
随着这些物理硬件的升级,计算机领域内便产生了OTT式的技术革新,诞生了分布式计算和量子计算机技术,而这两者的出现,也必将决定性的改变计算机资源供给端的情况。
分布式计算机技术,已经逐渐成为大数据领域底层IT架构的行业标准,分布式计算可以实现一个计算目标可以调配无限计算资源并予以支持,解决了大数据情境中运算量过大、超出单台物理机运算承受能力极限的问题,并且同物理计算资源协同调配,为后续的云计算奠定了基础。客观 的讲,分布式计算机技术使计算资源趋于无限。
而量子计算机技术将使单体计算能力拥有质的飞跃。但是在量子计算机核心技术尚未突破之时,人类面对呈现爆发式增长的数据束手无策….
在经过这漫长的探索后,人类现在决定先借助分布式计算技术实现新的一轮OTT式技术革新,而此举将不仅解决了海量数据存储与计算问题,还有希望帮助人类彻底摆脱计算资源瓶颈的束缚。计算资源无限,世界将会怎样….
但是从大数据技术的发展现状来看,真正的难点还是在于底层工具的掌握,由于发展尚处于初级阶段,还需要人们掌握大量的底层工具,这条道路因为走得人少所以才会显得泥泞不堪,只有将基础工具发展和掌握成熟之后,才可以降低使用者的门槛。
对于我们而言,这条路难么?真的很难!但是是值得我们客服这条路上的困难的,因为收益会非常的划算,这条路的难处在于要掌握很多底层工具,为什么?因为走这条路的人少,现在还是一条泥巴路,很难走,但是为什么是值得我们克服困难也要走下去呢,是因为只要量子计算机不出现、随着摩尔定律的失效、数据量还在增加,大量过路的需求会催生一条又一条高速公路,然后铺路的大公司设卡收税,泥巴路迟早会变成高速公路,但只要你先过去,就能看到别人看不到的风景。
从计算机由DOS系统到桌面系统,Python机器学习由源码到算法库,不一直都是这样么。
机器生产释放脑力,机器学习释放脑力
数据革命的本质
大数据分析技术有价值、数据分析技术更有价值,那整个数据科学知识内容体系中,最有价值的到底是什么?
如果从发现技术的角度看待问题确实很有意思,那我们不妨再来探讨一个问题,那就是从技术层面而言(非工作是否好找的角度),数据科学中最有价值的技术模块是哪个?
人工智能是数据养育的智能,其决策的核心是算法,人工智能的发展与十八世纪工业革命通过机器生产代替手工劳动从而释放人类的劳动力类似,数据智能将通过参与、代替人类决策的方式,释放人类脑力。而机器学习就是提供人工智能决策的算法核心。
机器学习算法的核心用途是挖掘事物运行内在逻辑和规律,就是把数据作为接受外部信息形式,用数据还原外部事物的基本属性和运行状态,用机器学习算法对其规律进行挖掘,还原客观规律。再应用规律辅助决策。
机器学习可以使得人工智能在人类基础重复决策领域代替人类参与决策。

算法的核心方法论,是取法其上,仅得为中,数据分析核心价值要有技术核心价值这杆大旗;不管小数据还是大数据,都是重分析。而伴随着Python的星期,催生出了进一步完善的基础设施,Python依然成为了标准的工具。
而Python最核心的技能就可以说是利用众多强大的算法库进行算法建模分析
 强人工智能、弱人工智能,还是人工智障
强人工智能、弱人工智能,还是人工智障
数据、算法、计算能力这三架马车所推动的人工智能技术发展,是否已经遇到了瓶颈
2018年1月我国国家标准化管理委员会颁布的《人工智能标准化白皮书》对人工智能学科的基本思想和内容作出了解释。认为人工智能应该是围绕智能活动而构造的人工系统,是一项知识的工程,是机器模仿人类利用知识完成一定行为的过程。
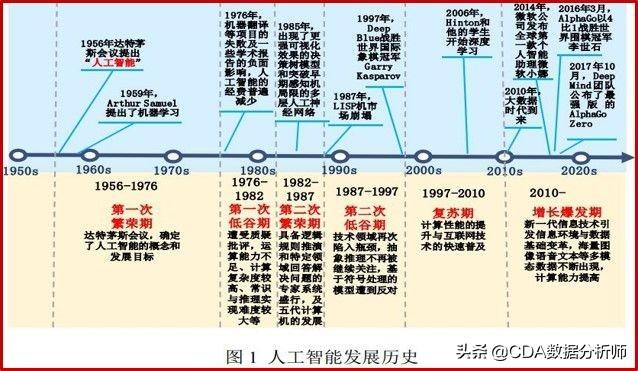
相对来说我国的人工智能的起步还是较晚,人工智能的发展阶段可以分为三个阶段,第一阶段是从20世纪50年代—80年代,在这一阶段人工智能刚诞生,但由于很多事物不能形式化表达,建立的模型存在一定的局限性。第二阶段是从20世纪80年代—90年代,专家系统得到快速发展,数学模型有重大突破,但由于专家系统在知识获取等方面的不足,人工智能的发展又一次进入低谷期。第三阶段是从21世纪初—至今,随着大数据的积聚、理论算法的革新、计算能力的提升,人工智能在很多应用领域取得了突破性进展, 迎来了又一个繁荣时期。
根据人工智能的发展定义,以及国家颁布的《人工智能白皮书》,人工智能可以分为两种,强人工智能和弱人工智能。
弱人工智能是并不能真正实现推理和解决问题的智能机器,这些机器表面看像是智能的,但是并不真正拥有智能,也不会有自主意识。但是这仍是目前的主流研究仍然集中于弱人工智能,并取得了显著进步,如语音识别、图像处理和物体分割、机器翻译等方面取得了重大突破,甚至可以接近或超越人类水平。
强人工智能是真正能思维的智能机器,并且认为这样的机器是有知觉的和 自我意识的,这类机器可分为类人与非类人两大类。从一般意义来说,达到人类水平的、能够自适应地应对外界环境挑战的、 具有自我意识的人工智能称为“通用人工智能”、“强人工智能”或“类人智能”
一般来说,在我们认为强人工智能的时代已经来临,只是尚未流行起来,但这时候,却还有一些有意思的观点,他们持反对的声音,认为人工不智能或者说是人工智障。
他们认为当我们在开车的时候,大脑在飞速的处理各种信息:交通信号、标志物、路面的井盖、积水;看到马路中央有一只狗在过马路时,我们会踩刹车;看到中央有一只鸟,我们会判断鸟会快速飞走,不用减速;如果是塑料袋,我们可以直接压过去;如果是大石头,我们就需要避让。这些都是我们通过经验的累积以及生活常识构成的。但是,人工智能却做不到这些。
目前人们所研究的人工智能是“狭义”人工智能。“真正的”人工智能需要能够理解食物之间的因果关系,比如警方在路上设置的锥标,哪怕是倒了,或是被压扁了,也要能够被识别出来。但目前的图形识别能力,哪怕是把障碍物换个角度,计算机识别起来都会很困难。而“狭义”人工智能走的是机器学习路线,换句话说,计算机会把路上所有物体(包括够、其他车辆、标志物、行人、塑料袋、石头等)都简单的看做是障碍物,同时计算和预测这些障碍物的移动路线,判断是否会和汽车的路线发生冲突,然后执行相应的动作。
那么问题来了……
当计算机无法理解物体的时候,也就意味着不可能100%准确预测物体的移动轨迹。比如,马路中央的狗。你很难预测它下一秒的位置,即使它目前正在向前狂奔。如果马路中央是一个孩子呢?同时,让计算机识别路边的交通指示牌也是一件十分困难的事情。当指示牌有破损、遮挡物等等,都会影响计算机的识别。
所以,目前的人工智能都属于“狭义”的人工智能,它的核心是基于大数据进行的学习。但在瞬息万变的现实世界里,由于计算机无法真正理解事物的相互关系,因此并不能处理出现的意外情况。
我们可以将无人驾驶分为五个级别:
辅助性自动驾驶(如自动刹车、保持车道、停靠辅助系统等)满足一定条件下,汽车可以自动驾驶,但需要驾驶员进行实时监控(如特斯拉的自动驾驶技术)满足一定条件下,汽车可以自动驾驶,驾驶员不需要实时监控,但要随时准备好接管驾驶。满足一定条件下,可实现无人看管的自动驾驶。完全实现无人看管的自动驾驶。
就目前来看,我们距离第五个级别的无人驾驶的距离还有非常遥远的一条道路要走,当然这条道路的未来,并没有人会知道是什么样子的。
在我看来,随着技术的发展,人工智能这条道路并非是走不下去的,只是这条道路比较困难,而且并不是说在人工智能完全达到强人工智能的时候才能造福人类,目前人工智能已经用于我们身边的多个领域,并且在不断的帮助我们,我们可以通过人工智能不断的帮助我们完善人工智能,达成一个不断的循环,只是需要很多对数据科学领域感兴趣的人,来不断的完善它们。
希望你看完这篇文章能够有所收获,如果有一些想法,希望可以一起讨论一下,谢谢。
【凡本网注明来源非中国IDC圈的作品,均转载自其它媒体,目的在于传递更多信息,并不代表本网赞同其观点和对其真实性负责。】























