









Pinot是一个适用于Web的实时数据分析系统,由LinkedIn设计开发,现在已经成为LinkedIn的分布式实时数据分析基础设施,支撑着LinkedIn内外30多个分析产品。LinkedIn的各种数据跟踪功能都是在Pinot的基础上实现的,如最近哪些用户查看了特定用户的资料,哪些用户在关注某个公司等。
据GigaOM报道,在LinkedIn还是一家初创企业的时候,其工程团队分成了若干不同的组,每个组使用的数据存储系统差别很大,如将Oracle的关系型数据库用于查询,而将Voldemort用于键值存储。但随着LinkedIn的日益发展以及用户数据的增多,这些不同的系统变得难以扩展。
Praveen Neppalli Naga是LinkedIn的一名项目经理。他告诉GigaOM,为了解决上述问题,他与其团队开始构建一个集中式系统。该系统既要能够整合LinkedIn的所有数据,又要能够简化以它为基础的数据密集型产品的构建过程。为了集中管理LinkedIn的数据,他们选用hadoop基础架构模型作为Pinot的基础,并根据需要做了修改。然后,他们就可以编写Hadoop脚本,检索建有索引的用户数据。
由于LinkedIn的数据维度众多,Pinot需要能够支持多种类型的索引。例如,一个人就读的大学是一个不会变化数据点,而他拥有的技能类型会发生变化,因此它们的索引方式应该不同。下面是Pinot的系统架构图:
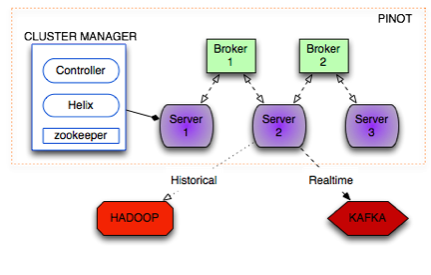
另外,为了能够快速准确的响应用户请求,LinkedIn工程团队还必须找到一种方法,既能保证与请求相关的最新数据随时可用,又能保证老数据的可用性,同时,老数据又不会混入新数据妨碍用户的查询。为了实现这个目标,他们借助Apache Kafka实现了实时数据索引过程。
据Naga说,经过了大约两年的开发,Pinot现在成了LinkedIn事实上的数据分析平台。他们正在评估将其开源,并围绕它建立一个开发社区,以推动它进一步发展。























