









在本文中,我们将简要介绍三种Apache处理工具:Flume,Kafka和NiFi。这三种产品都具有出色的性能,可以横向扩展,并提供插件机制,可通过自定义组件扩展功能。
Apache Flume
Flume部署由一个或多个使用拓扑配置的代理组成。Flume代理是一个JVM进程,它承载Flume拓扑的基本构建块,即源、通道和接收器。Flume客户机将事件发送到源,该源将这些事件成批放置到名为channel的临时缓冲区中,然后从该缓冲区中数据流到连接到数据最终目的地的接收器。接收器也可以是其他Flume代理的后续数据源。代理可以被链接,并且每个代理都有多个源、通道和接收器。
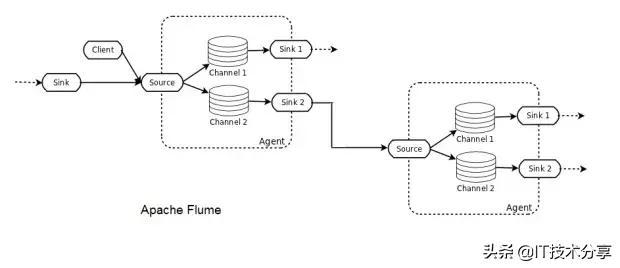
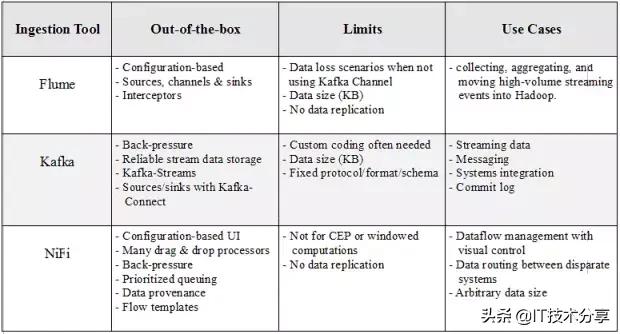
Flume是一个分布式系统,可用于收集、聚合流事件并将其传输到Hadoop中。它有许多内置的源、通道和接收器,例如Kafka通道和Avro接收器。Flume是基于配置的,它有拦截器来对通道中的数据执行简单的转换。
如果不小心,使用Flume很容易丢失数据。例如,为高吞吐量选择内存通道有一个缺点,即当代理节点关闭时,数据将丢失。文件通道将以增加延迟为代价提供持久性。即使如此,由于数据没有复制到其他节点,因此文件通道仅与底层磁盘一样的可靠性。Flume通过多跳/扇入扇出流提供了可伸缩性。对于高可用性(HA),可以水平扩展代理。
Apache Kafka
Kafka是一种分布式、高吞吐量的消息总线,它将数据生产者与消费者分离开来。消息被组织成主题,主题被拆分成分区,分区被跨集群中的节点(称为代理)复制。与Flume相比,Kafka具有更好的可扩展性和消息持久性。Kafka现在有两种风格:一种是“经典”的生产者/消费者模型,另一种是新的Kafka-Connect,它为外部数据存储提供可配置的连接器(源/接收器)。
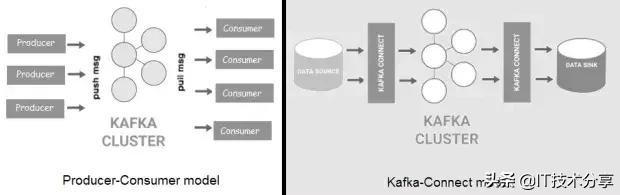
Kafka可用于大型软件系统组件之间的事件处理和集成。此外,Kafka附带了Kafka流,它可以用于简单的流处理,而不需要像Apache Spark或Apache Flink那样的单独集群。
由于消息被持久化在磁盘上,并且在集群中被复制,因此数据丢失情况不像Flume那样常见。也就是说,无论是使用Kafka客户端还是通过Connect API,生产者/来源和消费者/接收器通常都需要自定义编码。与Flume一样,消息大小也有限制。最后,为了能够进行通信,Kafka的生产者和消费者必须就协议、格式和架构达成一致,这在某些情况下可能会有问题。
Apache NiFi
与Flume和Kafka不同,NiFi可以处理任意大小的消息。在基于Web的拖放式用户界面后面,NiFi在集群中运行,并提供实时控制,使您可以轻松管理任何源和任何目标之间的数据移动。它支持不同格式、模式、协议、速度和大小的分散和分布式源。
NiFi可以用于具有严格安全性和合规性要求的关键任务数据流中,在那里我们可以可视化整个过程并实时进行更改。在撰写本文时,它有近200个随时可用的处理器(包括Flume和Kafka处理器),可以进行拖放、配置和立即投入使用。NiFi的一些关键特性是优先级排队、数据跟踪和每个连接的背压阈值配置。
尽管NiFi用于创建容错生产管道,但它还没有像Kafka那样复制数据。如果一个节点发生故障,那么可以将流定向到另一个节点,但是排队等待故障节点的数据必须等待该节点恢复。NiFi不是一个成熟的ETL工具,也不是复杂计算和事件处理(CEP)的理想选择。为此,它应该连接到Apache Flink,Spark Streaming或Storm等流式传输框架。
组合
没有哪个工具 满足您的所有要求。组合以更好方式执行不同操作的工具可以实现功能的增强,并提高处理更多场景的灵活性。根据您的需求,NiFi和Flume都可以充当Kafka生产者或消费者。
Flume-Kafka集成非常受欢迎,它有自己的名字:Flafka(我不是这样做的)。Flafka包括Kafka源,Kafka通道和Kafka池。结合Flume和Kafka,Kafka可以避免自定义编码并利用Flume经过实战考验的资源和接收器,通过Kafka通道的Flume事件将在Kafka代理中进行存储和复制,以实现弹性。
组合工具可能看起来很浪费,因为它似乎在功能比较重叠。例如,NiFi和Kafka都提供了代理来连接生产者和消费者。但是,它们的做法不同:在NiFi中,大部分数据流逻辑不在生产者/消费者内部,而是在代理中,允许集中控制。NiFi的构建是为了做一件重要的事情:数据流管理。通过两种工具的结合,NiFi可以充分利用Kafka可靠的流数据存储,同时解决Kafka无法解决的数据流挑战。
总结:
【凡本网注明来源非中国IDC圈的作品,均转载自其它媒体,目的在于传递更多信息,并不代表本网赞同其观点和对其真实性负责。】




















